模型管理
模型管理是系统的核心模块, 用于统一维护模型能力、计费方式、权限范围和最终对外调用入口
适用角色
- 管理员: 仅管理员可进入, 负责维护平台可用模型和统一计费规则
功能说明
提供商与真实模型: 每个模型都归属于一个提供商, 并对应一个真实可调用的上游模型
模型名称: 模型名称是系统内部统一对外的调用名称, 调用方只需要记住这一套名称即可
模型类型: 可区分文本、绘图、识图、语音、向量、视频、多模态、通用等能力, 方便后续授权和筛选
模型地址与模型路径: 可按实际情况覆盖默认地址和路径, 便于接入不同上游线路
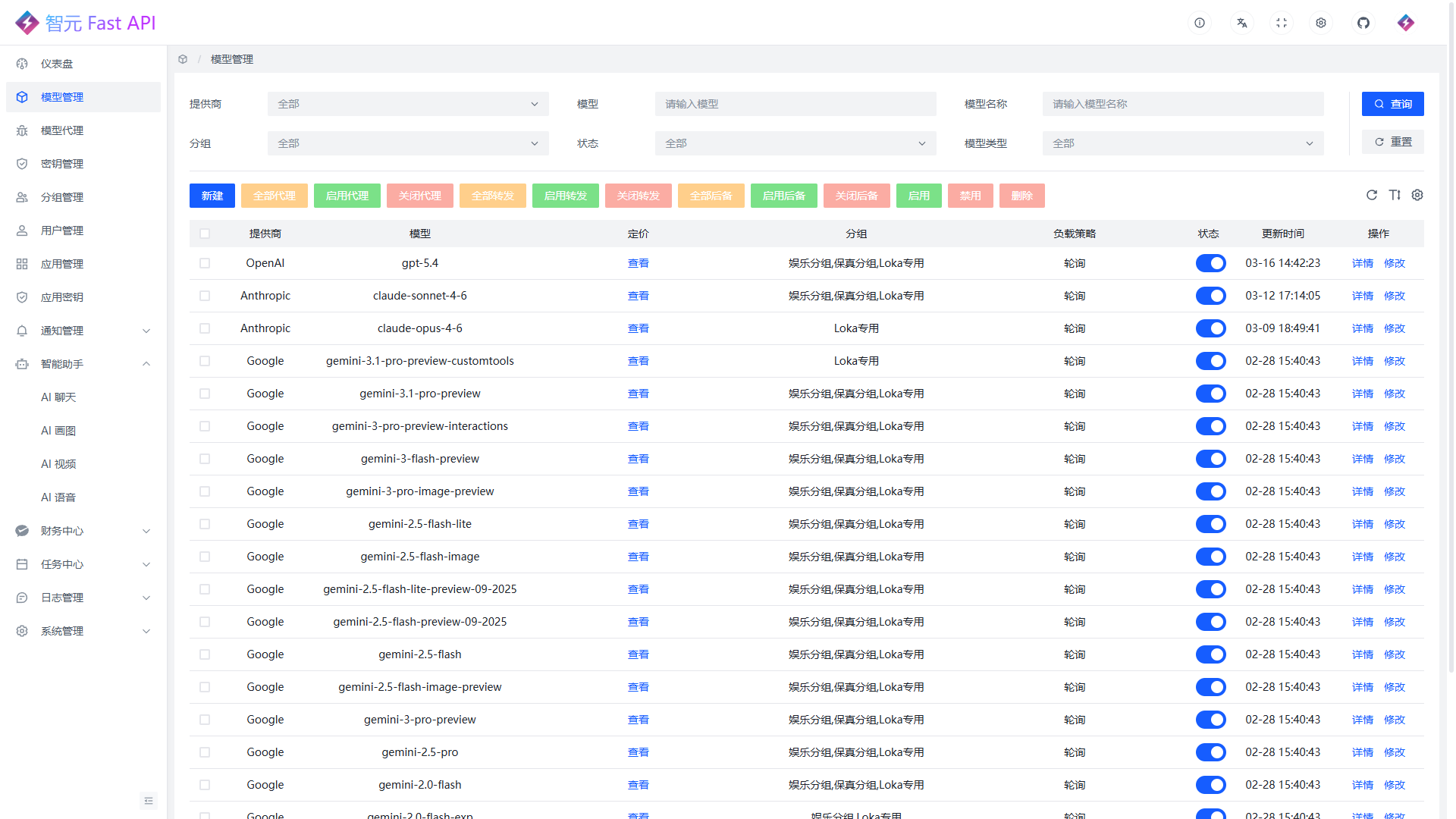
模型广场: 可用卡片方式浏览平台可用模型, 支持按关键字筛选, 并查看模型类型、提供商、计费方式和价格摘要
模型信息复制: 在模型广场中可快速复制模型名称, 方便配置应用、分组或调用参数
价格展示: 模型广场会展示常用输入、输出、读取、写入等价格信息, 需要完整价格时可进入详情继续查看
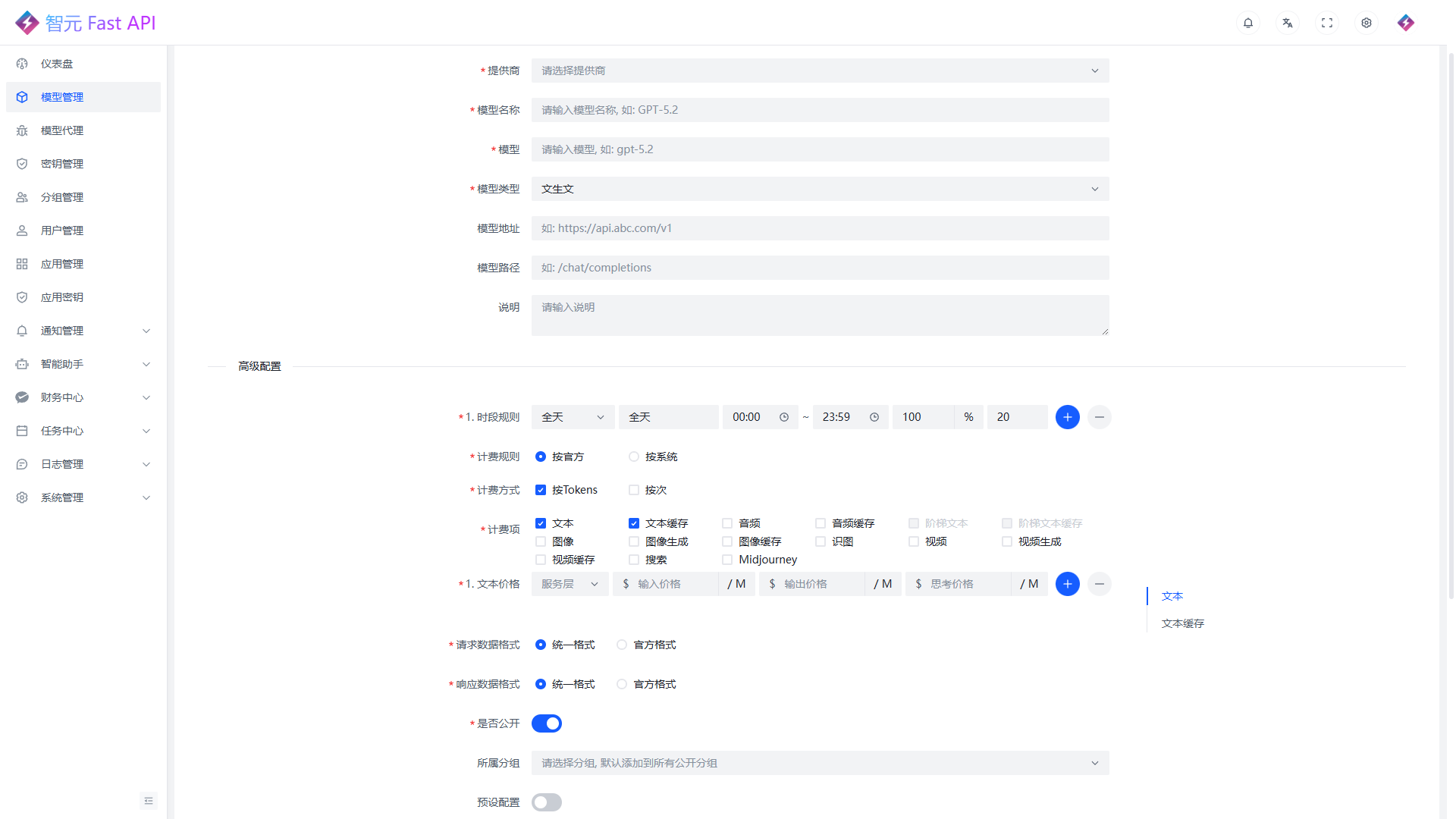
计费规则: 支持按官方返回数据计费, 也支持按系统统一口径计费
计费方式: 可按 Tokens 计费, 也可按次计费, 适合不同类型的商业方案
多计费项: 支持文本、缓存、识图、图像、音频、视频、搜索等多种计费项自由组合
服务层与模式计费: 支持按不同服务层、思考模式与非思考模式分别设置价格
阶梯计费: 支持按用量区间配置不同文本价格, 适合做更细的套餐和商业定价
时段计费: 支持按全天、工作日、周末或自定义时段设置不同折扣, 适合做峰谷价、活动价和限时优惠
细分价格项: 支持按搜索、视频分辨率、图像分辨率等维度设置差异化价格, 适合更精细的商业定价
请求与响应格式: 可分别设置请求格式和响应格式, 便于统一接入或按上游原生格式透传
不同提供商的价格配置差异
默认通用配置: 大多数兼容 OpenAI 标准的平台, 都可以按通用的文本、缓存、图像、音频、视频、搜索、按次等方式配置价格
OpenAI / Azure / Claude / DeepSeek / 豆包 / 通义千问 / 智谱 GLM 等常见平台
- 更适合按文本、缓存、按次、时段折扣、阶梯计费等通用方式配置
- 如果同一个模型既要做 Tokens 计费, 又要做按次计费, 也可以组合配置
Gemini / Google 系
- 图像生成价格支持按不同分辨率方案细分配置
- 更适合对不同输出尺寸分别定价
火山引擎
- 视频生成价格支持更多分辨率组合
- 可区分不同视频输入场景做更细的价格配置, 更适合视频模型运营
Midjourney 类能力
- 支持按不同动作分别配置价格, 例如绘图、放大、变换、重绘、变焦、换脸等
- 适合把不同操作拆成独立收费项
搜索类能力
- 可按不同上下文档位分别配置价格
- 适合对高上下文、低上下文等不同搜索模式区分收费
识图 / 图像生成 / 视频生成
- 这类能力可按模式、尺寸、清晰度等维度细分价格
- 更适合多媒体模型做精细化商业定价
公开范围: 模型可设置为公开或非公开, 决定是否能直接被授权给用户、分组或应用
所属分组: 可把模型加入指定分组, 让分组统一控制模型权限
默认参数与预设: 可设置 system 角色、提示词、流式能力和参数范围, 降低调用方传错参数的概率
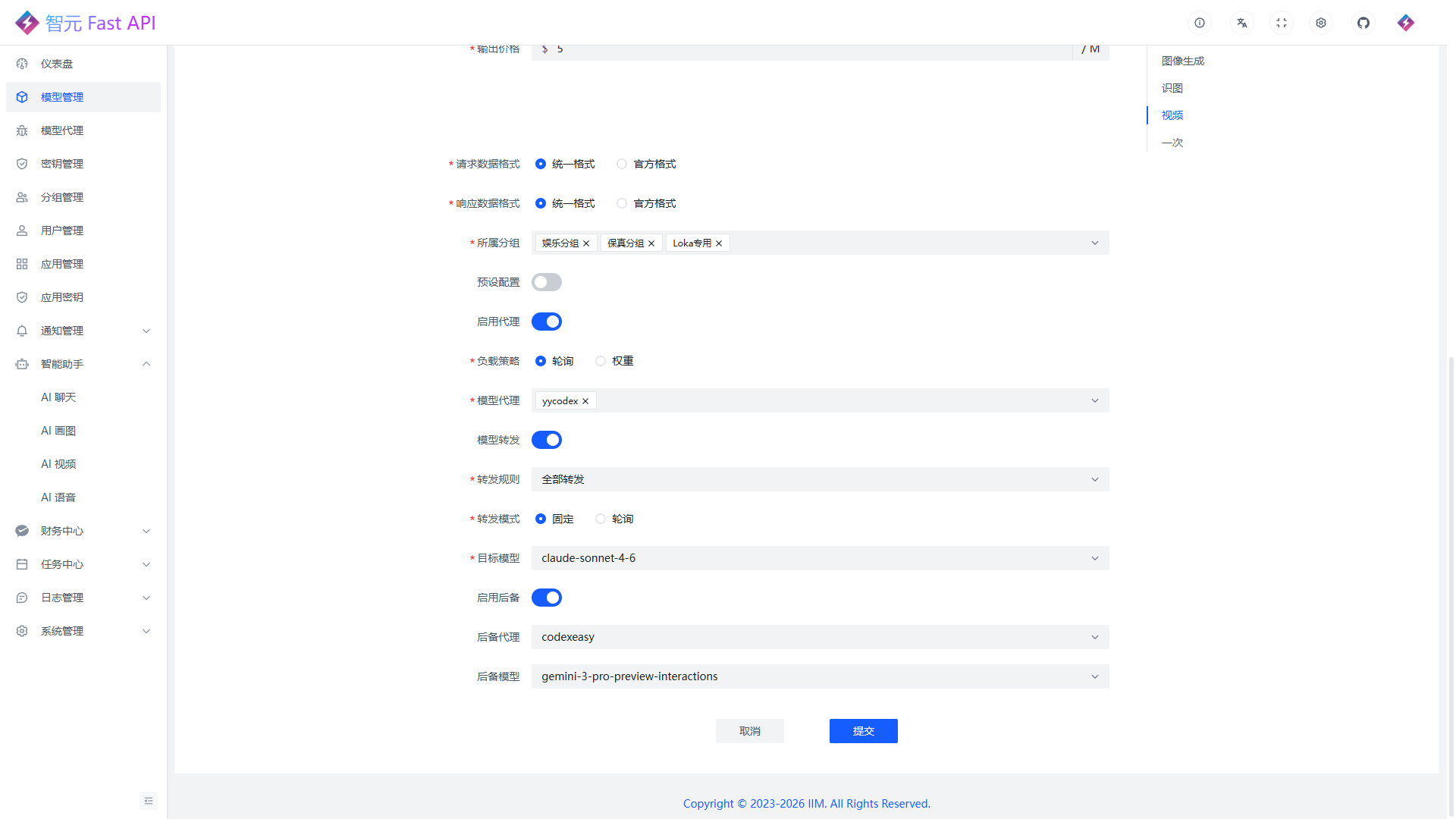
启用代理: 模型可绑定一个或多个模型代理, 通过轮询或权重方式分流请求
模型转发: 可按关键字、内容长度、已用额度等条件自动切换到目标模型
多模型转发: 支持固定转发或轮询转发多个目标模型, 适合做多线路分流和多模型兜底
后备能力: 当当前模型或代理不可用时, 可自动切换到后备模型或后备代理, 保持服务连续性
管理用途
统一维护模型名称、能力、价格和授权范围, 避免不同业务各自单独定价
通过模型广场快速查找可用模型和价格信息, 降低用户选型成本
给不同分组、会员和应用提供稳定一致的调用入口, 让前台调用名称保持不变
可按 Tokens、按次、多计费项、阶梯区间、时段折扣等方式组合定价, 适合做标准套餐价、阶梯价、峰谷价和活动价
可按服务层、思考模式、搜索、视频分辨率、图像分辨率等维度拆分价格, 更适合高低配模型混合运营
方便后续做模型切换、扩容、线路分流和更灵活的商业化定价